Sentiment Analysis with Deep Learning
In this blog post we are going to review the well-known problem of Sentiment Analysis, but this time we will use the relatively new approach of Deep Learning.
Even though some of the most famous applications of the deep neural networks are related to image processing, many recent researches show awesome results resolving nature language processing problems.
Recurrent neural networks (which we are about to explore) are a subclass of neural networks,
designed to perform a sequences recognition or prediction. They have a flexible number of inputs and they allow cyclical
connections between their neurons. This means that they are able to remember previous information and connect it to the current task.
Long Short Term Memory networks (LSTM) are a subclass of RNN, specialized in remembering information for a long period of time. More over the Bidirectional lstms keep the contextual information in both directions.
Here you can find detailed explanation how LSTM works.
In this post we will concentrate on the application part.
Tools
Before we start we need to make sure we have the following tools installed:
- Python
- TensorFlow - Google’s open sourced numeric computational library
- Keras - Neural Network Framework, which can run on top of TensorFlow
- Numpy - Package for scientific computations
- Pandas - Package providing easy-to-use data structures and data analysis tools
Approach
See below a simple diagram of how we will design our deep neural network.
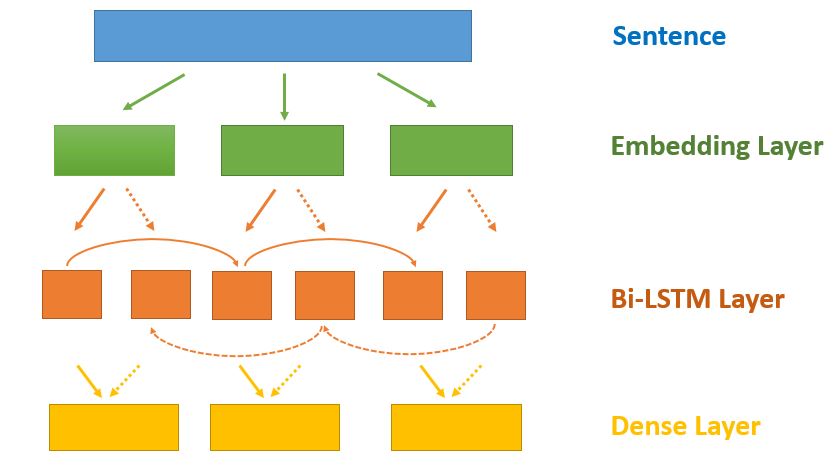
Figure 1 - Architecture Bidirectional LSTM
Let’s divide our work in two main steps:
- Pre-process training data
- Create Keras Model
For this tutorial I’ve used Sentiment data by Sonam Srivastava.
Preprocessing
In order to make our life easier we can merge the two files (one with positive and one with negative examples) into one csv file with one column called text and another called sentiment - 1 for positive examples and 0 for negatives. We should also randomize the order.
The next thing to do is to prepare our data for the neural network.
We can simply use Keras preprocessing methods.
import numpy as np
import pandas as pd
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential, load_model
from keras.layers import Dense, Embedding, LSTM, Bidirectional
from sklearn.model_selection import train_test_split
from keras.utils.np_utils import to_categorical
import re
data = pd.read_csv("text_emotion.csv")
tokenizer = Tokenizer(num_words=2000, split=' ')
tokenizer.fit_on_texts(data['text'])
X = tokenizer.texts_to_sequences(data['text'])
X = pad_sequences(X)
Y = data['sentiment']
# We can then create our train and test sets:
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 42)
In Keras, we can define our deep network as a sequence of layers. As described in the image above, we need to have three layers:
- Embedding Layer - modifies the integer representation of words into dense vectors
- Bidirectional LSTM Layer - connects two hidden layers of opposite directions to the same output
- Dense Layer - output layer with softmax activation
model = Sequential()
model.add( Embedding(2000, embed_dim = 128, input_length = X.shape[1], dropout=0.2))
model.add( Bidirectional( LSTM(lstm_out = 196, dropout_U = 0.2, dropout_W = 0.2)))
model.add( Dense(2, activation = 'softmax'))
model.compile(loss = 'sparse_categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.fit(X_train, Y_train, nb_epoch = 7, batch_size = batch_size, verbose = 2)
This deep neural network gives us accuracy of 73%.
Note: Feel free to play with the Hyperparameters as much as you like
We will cover this topic in another blog post.
Stay tuned!
